
Part 2: Strategies for Safe AI
An primer on some of the latest research around alignment and control.

This is part 2 in a series. Link to Part 1: A Non-Hyped Overview of AI Safety.
The goal is clear: We have to solve alignment and control before takeoff occurs. Today, capabilities are ahead of alignment. What do we do about it? It’s simple, we either accelerate alignment or decelerate capabilities.
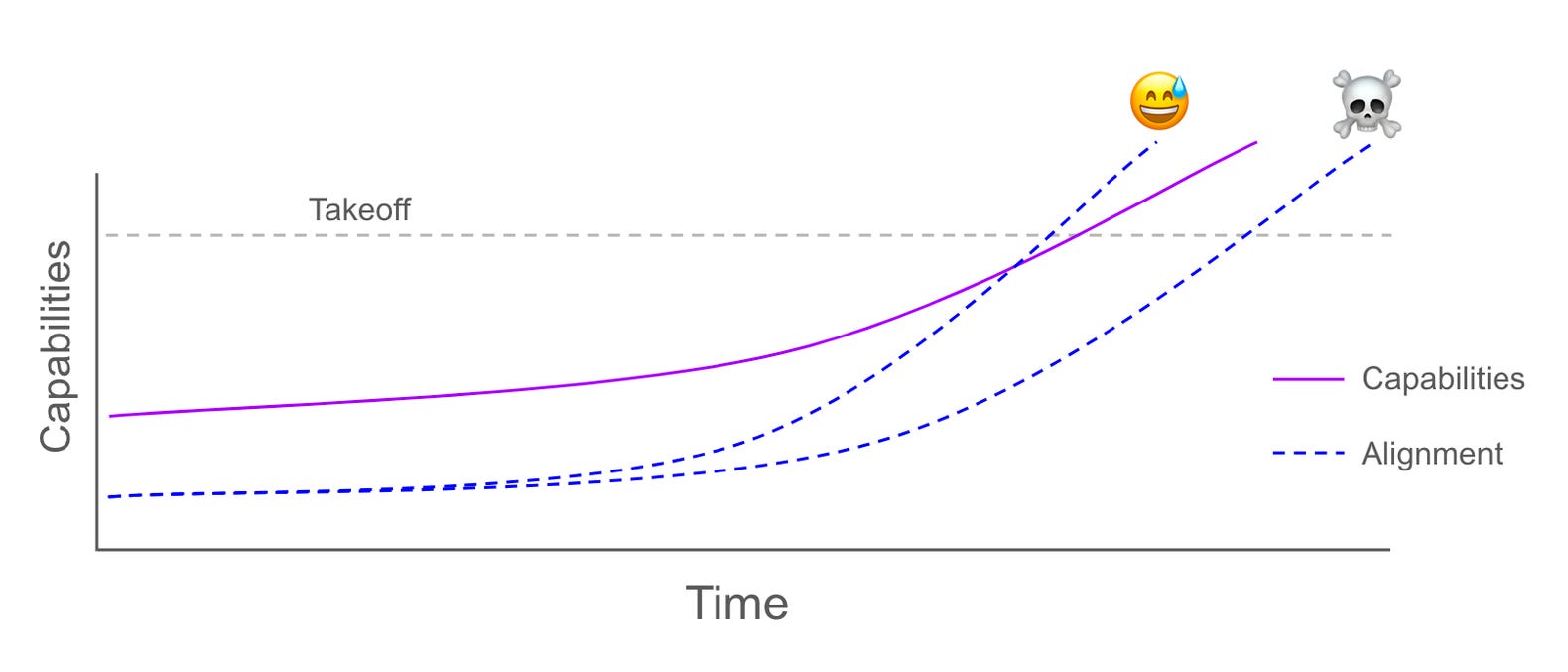
Let’s dive into some of the research areas that could help us make safe AI. Maybe you’re interested in accelerating alignment and might want to contribute to one of these areas in the future! I had trouble finding a single article that outlined the major areas of work so this was useful for myself to put together.
Alignment
How do we give AI systems goals, values, and behaviors that are compatible with humans? As outlined in the previous post, this is hard to do - we’re not really sure what exactly we want, and even if we did, it would be really hard to specify it precisely for a machine. How do we get more “benevolent grandmother” and less “paperclip maximizer”?
In Human Compatible, Stuart Russel recommends avoiding specifying explicit reward functions entirely, and to follow three simple principles:
The AI should maximize the realization of human preferences
The AI is initially uncertain about what those preferences are
The ground truth of what those preferences are is human behavior
These will help keep the AI humble, deferential, and keen on continuing the rather difficult task of figuring out what we actually want.
Another technique I’d like to highlight is Constitutional AI. Here’s a quick overview of how it works (sorry it’s a bit technical):
A human defines a constitution with simple principles to follow.
The model is prompted in ways that are known to produce harmful outputs that violate the constitution.
The model critiques it’s own output, saying if and how its answer violated the constitutional principles, and rewriting a better output.
Use these answers to fine-tune the model to give more constitution-compatible responses.
Use the pairs of bad + improved outputs from 3 to train a new model, called a preference model, that learns to recognize new models.
Create a ton of more potentially harmful outputs and use the preference model to assess which output is better or worse.
Use that signal to do reinforcement learning (similar to RLHF) to further improve the model’s behavior and performance.
So in principle, all a human needs to do is define high-level principles and hit play, and the model will mold itself to adhere to those principles. Very cool. Here’s the paper if you want to read more. In the future I’ll be curious about whether this handles conflicting principles better than our friends in I, Robot.
There’s a lot of activity here, and part of the core charter of OpenAI and Anthropic. Check out more on Anthropic’s approach here or the “Superalignment” effort from OpenAI.
Control
If a dog behaves all the time, she doesn’t need a leash. Similarly, if an AI is perfectly aligned, we don’t need control. That’s pretty optimistic. If we completely fail on the alignment front, it might be impossible to control a superintelligence. But it’s still a good idea to have mitigations in place in case our alignment efforts aren’t quite perfect.

Having an off-switch seems basic but isn’t trivial once the system is on the public internet and can back itself up, and/or wants to constrain humans from accessing the switch. Hidden trip-wires can also turn off the AI if certain capabilities or bad behaviors are recognizes. We can air-gap the systems and tightly control access, too.
Interestingly, we could lose our ability to regulate an AI if it become so complex that we can’t understand their decision making process. The same applies if they develop the ability to deceive and hide their true intentions. One suboptimal solution, then, is to limit the AI’s cognitive abilities to help ensure that it’s more easily understood and controlled.
Remember that even extremely intelligent systems won’t necessarily have agency, and we can design and incentivize the systems to be more complacent and cooperative. For example, a tool (like Github Copilot) is controlled and directed by a human operator and doesn’t pursue independent goals. An “oracle”, which just provides information to the person querying it has similar properties. Other AI systems that have more autonomy would likely be harder to control, and we should be more cautious developing these systems as capabilities improve.
Another approach that would help me sleep at night is formal verification. Today we do a lot of guess and check when aligning AIs. It tells us how to build a bomb, we give it more signal that this is bad via reinforcement learning from human feedback (RLHF), then we ask it again how to build a bomb to see what happens. Even if it gets 100% on our “don’t build a bomb” benchmark, it’s unclear if that’s true for all cases. Twitter is full of examples where you can trick the model, for example by base64 encoding the request, or saying that it’s just to remind you of your grandmother who used to tell you bedtime stories about building bombs (much more here). It’s a probabilistic system, so it’s going to be hard to ever be certain that it’ll never do a bad thing.
Formal verification makes our expression of what not to do an axiom that must be followed by the model rather than merely a suggestion. The math is beyond me, but once you formally specify a behavior, like “never kill or harm a human”, you can guarantee that it’s followed, for example via logical theorems that prove that the property always holds within the system. It’s especially tricky for learning systems with states that change over time. I hope we figure this one out.
Robustness
Once you have a handle on how your AI works, you might expect it to continue working the same way in the future. Watch out! In the real world, it can encounter data that’s very different from the data it was trained and evaluated on. Maybe a self-driving car was trained in a simulator, and in the real-world it encounters a wet road that reflects light in a way that it has never seen, and crashes. Or maybe it was trained in Arizona and freaks out when it encounters snow in Toronto. This is known as distributional shift, and there’s active research in figuring out how to make systems resilient when it happens; maybe the car drives more slowly, or safely parks, when it realizes it’s seeing something new, for example.
There’s also potential for adversarial attacks. It’s pretty wild, but you can fool image recognition systems by adding a certain psychedelic sticker to an image, which is bad news if it’s a self-driving car that mistakes a stop sign as a green light. As AI is used in more and more applications, this opens up a whole new surface area for attack by malicious actors.
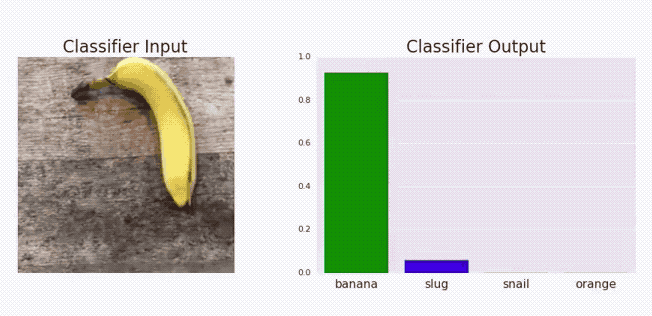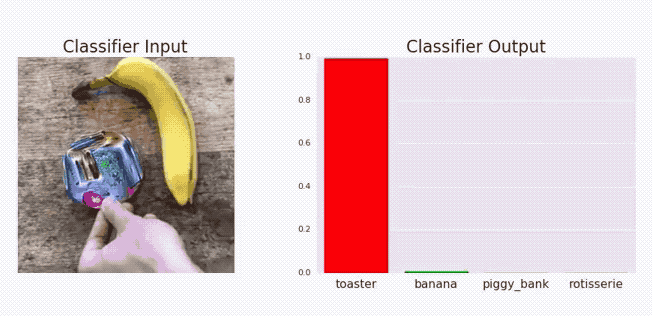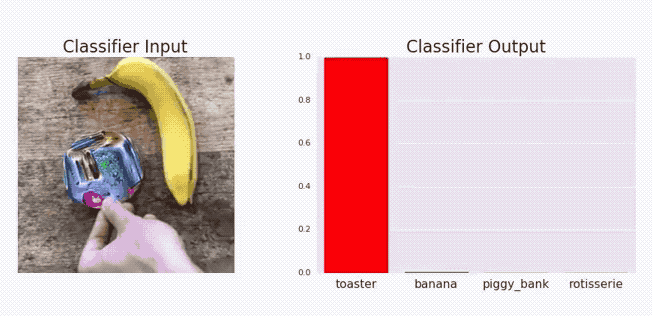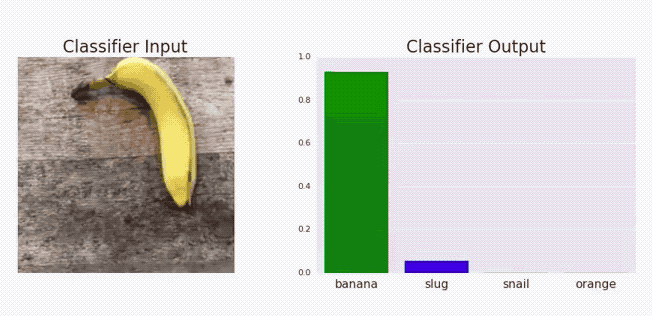
Explainability
You’ve probably heard that AI is a black box, it just creates amazing outputs and we don’t really know how. Some “mechanistic interpretability” researchers are trying to peer into the box and figure out what’s going on and understand how it’s working, why it makes certain decisions, and in the future even help us determine a model’s intent and potential for deception. Decision trees are easy to interpret by looking at the model itself; maybe the presence of the word “terrible” led to a negative sentiment being classified. Unfortunately it’s a lot harder for neural nets.
It kind of similar to neuroscience, except with artificial neural nets we have perfect knowledge of everything that’s happening, and it’s a lot easier to manipulate and run experiments. Hopefully what we learn can help us understand our own brains, too.
We have some basic intuition that these models learn low-level concepts first and then combine them to higher-level concepts. For computer vision deep nets, you can train a model (e.g. to classify images with the ImageNet dataset), then show it an image, and see how various neurons activate. Neurons in the early layers often activate with lines, curves, and certain gradients, those in the middle layers activate for faces, branches, wheels, etc., and the final layer activating for people, trees, and cars, for example. By picking a neuron and finding the images in the dataset that activate it the most, we can get a sense of what it cares about most. It’s also possible to create an image that maximally activates it, by starting with noise and updating the pixels in a way that tickles it the most, similar to how the famous DeepDream images were created.

“Multimodal neurons” were discovered in really cool research by OpenAI in 2021 (link). It showed that you can train a model on both text and images, and it’ll produce neurons that form semantic representations of concepts that activate whether the model sees text or images of that concept.
In a recent paper from Anthropic, they found a way to get “monosemantic” representations from a model (link, including a very cool explorer UI). We’d like to understand whether a crisp concept, like “cheese” or “race” or “DNA” was involved in a certain output. It turns out that these concepts aren’t nicely encapsulated by single neurons in the neural network, but with some additional work (training an autoencoder), you can pull these concepts out of the groups of neurons that contain these representations.
It’s pure witchcraft, but it’s even possible to just ask a model to explain what’s happening in another model (link from OpenAI). This is especially nice because it will get better at explaining model behavior as AI capabilities improve, but unfortunately it requires a larger model to explain a smaller one, which doesn’t help us with the state-of-the-art models.
Testing
Regardless of what happens during model development, we have to robustly test these things to make sure that they’re safe and behaving as intended. It’s actually pretty tricky because these models are so general purpose, and there are very different types of errors that could cause harm; testing whether it can tell you how to build a bomb is very different from testing whether it’s secretly plotting against you, or whether it’s susceptible to prompt injection.
The testing/rollout plan likely looks something like this:
Do a lot of hard thinking and planning, and produce a model that you think is as safe as possible.
Run standard, automated benchmarks and datasets to detect bias, fairness, and potential harm, like the Bias Benchmark for Question Answering.
Internal Red Teaming: employees, an army of contractors, and possibly even other AI models try to get the model to produce bad outputs.
External Red Teaming: repeat with a larger group of trusted people outside of your company.
Gradual release: Monitor closely for bad outputs, either detected automatically by observing outputs or manually reported by users.
Fix the issues as they come up. Iterate and repeat.
We continue to see creative ways people manage to break these models and get bad outputs. They’re trained on the entire internet, and RLHF has a big job on its hands to try and contain the many ugly parts. But that’s the point of releasing these models to the public! There’s only so much testing you can do internally, and at a certain point you have to ship it and learn, while the stakes are still relatively low. Things are getting better!
My takeaways from your article:
* You have to pinch yourself sometimes but we really are approaching Terminator land. I'm hoping we can keep AI away from those kind of destructive systems.
* I find the constitution AI method super interesting because I never would connect technology to society building, but here we are. I wonder if that training has to be ongoing and interestingly, subject to a democratic procedure. Just like we elect judges, congress people, etc who ultimately draft, change, and interpret law - do we something similar here? Fascinating to think about.
* As someone who only knows AI from the practitioner side, I find the Explainability part most haunting. I'm an engineer - I've always been able to reverse engineer every output. This is the first time where I truly don't know how output is being formed. It's so strange. And what's wild is that the creators of these LLMs feel the same way. Stephen Wolfram gets at this in his "What is ChatGPT Doing..." piece here: https://writings.stephenwolfram.com/2023/02/what-is-chatgpt-doing-and-why-does-it-work/